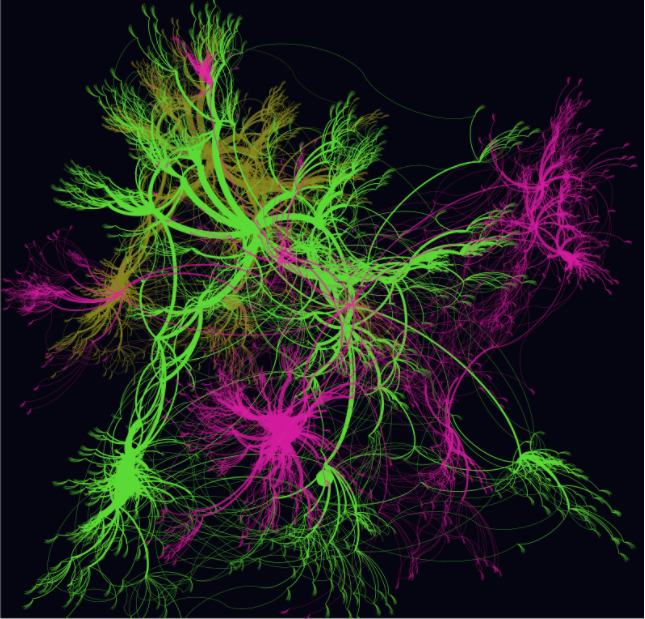
Behind the scenes of search and recommendation engines – some familiar, like Google Maps lurk deep and complex forests just like this one, grown from the principle of graph traversal.
If you’re a data scientist, you’ll have heard the term before. If not, say hello to one of the fastest-growing methods of data analysis in the market. Graph traversal offers a way of exploring data, which is traditionally formatted in rows and columns, as a hierarchical network: think a series of neurons, or roots of a tree. The resulting data networks exploit the fact that the value of data lies not only in the data points themselves but also in the connections between different data points.
>See also: The rise and impending fall of storage area networks
A London-based example: while an alphabetical list of all the tube stops in London is of little use to a commuter, a map of how these stops relate to each other in space is rich in meaning.
Being such powerful tools, data networks are experiencing a resurgence within the data science world. A recent survey of a global selection of entrepreneurs and developers by IBM showed a large proportion are adopting graphical analysis: over 40% of the companies questioned had recently transitioned to using graph databases for their analytics.
A unique application of graphical data analysis is its ability to recommend. Put simply, graph databases store data in the form of ‘nodes’ and ‘edges’ to create a mesh of information.
When paired with an adept algorithm that is written to navigate the mesh in a certain way, new insights can be extracted from the dataset that would not have been available if the information was stored in list. So, for a recommendation engine like Sparrho, academic papers are ‘nodes’, linked by ‘edges’ such as similarities in language and content. If a user ‘pins’, or likes, a node, and that node is related to another, chances are that user will want to read it.
Sparrho takes it one step further – users are ‘edges’ too, shaping the site’s data networks via what they ‘pin’. This algorithmic blend of artificial intelligence combined with human curation is growing more and more common, reflecting two important movements in data and computer science. The first is our unprecedented ability to collect amorphous masses of data and shape it into information that can inform our decisions. The second is our evolving needs, as a society, when it comes to quickly accessing relevant information. Quite simply, the way we ‘search’ is changing.
>See also: How the Internet of Things is impacting enterprise networks
It’s a common question on millennials’ lips: how did preceding generations survive without the ability to instantly access almost any piece of data, important or otherwise, at the touch of a button? Well, before now, the data just didn’t exist.
A quick Google search confirms it; this year, collective global internet use has reached one Zetabyte (10007 bytes), barely 30 years after the worldwide web was created. As a result, the amount of data being generated worldwide is increasing at an exponential rate: 90% of all of the world’s data was generated in the past two years.
The challenges that the data present are almost as vast as the data themselves. Quite apart from morality and security questions – is it safe for medical data to be in the hands of private companies, for example – new technical challenges are also emerging.
How do we easily get access to the data we want, while filtering out the white noise? And how do we extract deeper meaning and value from complicated, Russian doll-type datasets?
Regarding the first question, it is no coincidence that the most valuable company in the world is now a search engine. Google, which has only just celebrated its 19th birthday, is worth $520bn: just under a billion pounds for every day of the year.
Google’s algorithms are extremely effective at scanning vast amounts of content, from all over the web, to score it against specific criteria and return it in a page ranking. But as the amount of data accessible continues to explode in both size and complexity, keyword searching is no longer always the most adequate way to get the information you seek.
>See also: 8 predictions for business networks in 2017
This is nowhere more true than in scientific research. In line with the global increase of data, scientific output is also increasing exponentially; the rate of papers uploaded onto arXiV has been steadily climbing since the early nineties (see figure below).
For scientists, this means that staying abreast of new findings, in both your field and those adjacent, is a harder task. No longer can researchers be confident that a regular scan of one or two journals will keep them informed. Nor can they rely on keyword alerts to keep them broadly informed of the evolving scientific landscape.

Sparrho discovered this early on when they began asking scientists what they felt they needed to help them in their career. “There was a very clear focus on staying up to date, staying on top of a field or a sub-field in a way that provides a continuous feed that is tailored to the scientific user.
The team realised that scientists needed something better than a keyword search. The ability to discover relevant work, from all possible sources of scientific publications, was far more valuable.
But how does one build a discovery tool distinct from a search engine? By creating an exclusive scientific database from which to draw results. Over 45,000 journals are continuously scanned and their contents incorporated into data networks: the header image represents less than 0.001% of the Sparrho database. The degree of connectivity between papers is determined by a combination of textual similarity (called term frequency-inverse document frequency), author similarity, and user interaction with papers, via ‘pinboards’, on the Sparrho site.
>See also: Future of the NHS: new technologies and the networks behind them
Pinboard collections send the strongest signal to the algorithm, while weaker signals come from what users choose to read; whether they open an abstract, where they click. Each piece of data is relentlessly collected and funnelled to the algorithm to tailor the user experience.
But it’s the information provided by human expertise that is the most important data fed into the algorithm. Knowledge about how scientists judge the relevance of certain papers is more powerful than anything a computer can extract based on keywords alone..
Once the blend of networks is created, the algorithm traverses the different arms of the data network via a ‘breadth-first-search’ approach; papers that are deemed most similar are checked first, before the algorithm takes greater risks by pursuing deeper tiers of the network.
The output? The algorithm returns to the user paper recommendations that are related to their interests and are judged as important by others with similar interests, but that may contain different keywords and come from fields of research that the user may not have thought to explore. Simply put, users are able to discover rather than find.
>See also: Future of the NHS: new technologies and the networks behind them
Science is unlikely to find itself in a position where we must “overwrite the tapes” have published research. Ideally, the roots of the tree of knowledge will remain steadfast while new buds continue to burst. But as the tree becomes larger and more complex, scientists and the general public will inevitably have to embrace new methods of parsing global scientific output.
Across all sectors, the rapid advancements underway in computer and data science will transform the way we sort, process and query our data: it’s a revolution that’s only just getting started.
Sourced by Dr. Vivian Chan is CEO and co-founder of Sparrho




